Inside PersonaPlex: NVIDIA's AI That Can Talk and Listen at the Same Time
NVIDIA's PersonaPlex is a 7B full-duplex conversational AI model that doesn't wait for you to finish talking before it starts responding. It listens, speaks, and reacts simultaneously — handling interruptions in under 250 milliseconds while letting developers customize any voice or role. Here's how it works, why it matters, and what it means for the future of voice AI.

The Moment You Realize It's Just a Pipeline
There's a moment every one of us has experienced with a voice assistant. You're talking, and the words are flowing, and you're halfway through explaining what you actually need — and then the assistant just... starts talking over you. Or worse, it sits there in dead silence for two full seconds after you stop, as if it's gone to grab a coffee before bothering to respond. You know the feeling. It's the moment you remember you're not talking to a person. You're talking to a pipeline.
For years, this was just how voice AI worked — and most of us accepted it. Speech recognition improved, language models got smarter, and synthetic voices started sounding remarkably human. But none of that fixed the actual conversation. The rhythm was off. The timing was wrong. The feeling of being heard was completely absent. Then, in January 2026, NVIDIA released PersonaPlex — a model built from the ground up to change how machines hold a conversation. And for the first time, the gap between talking to an AI and talking with one started to close.
The First Minute Changes Everything
The first thing you notice when you talk to PersonaPlex is what it does while you're still speaking. It doesn't wait. It hums along. It drops a quiet "uh-huh" at exactly the right moment — not a programmed delay, but a contextually appropriate backchannel that tells you, somehow, that this thing is tracking what you're saying. When I paused mid-sentence to collect a thought, it waited. When I interrupted it in the middle of an answer, it stopped — not after a beat, not after finishing its sentence, but almost instantly, in about a quarter of a second.
That quarter-second matters more than it sounds. Google's Gemini Live, one of the most polished voice AI products on the market, takes roughly 1.3 seconds to handle the same kind of speaker switch. In human conversation, 1.3 seconds of dead air after an interruption feels like an eternity. It's the uncanny valley of dialogue — close enough to feel wrong rather than impressive. PersonaPlex collapses that gap to something that feels instinctive. You stop noticing the technology and start just... talking.
The Trade-Off That Nobody Could Solve
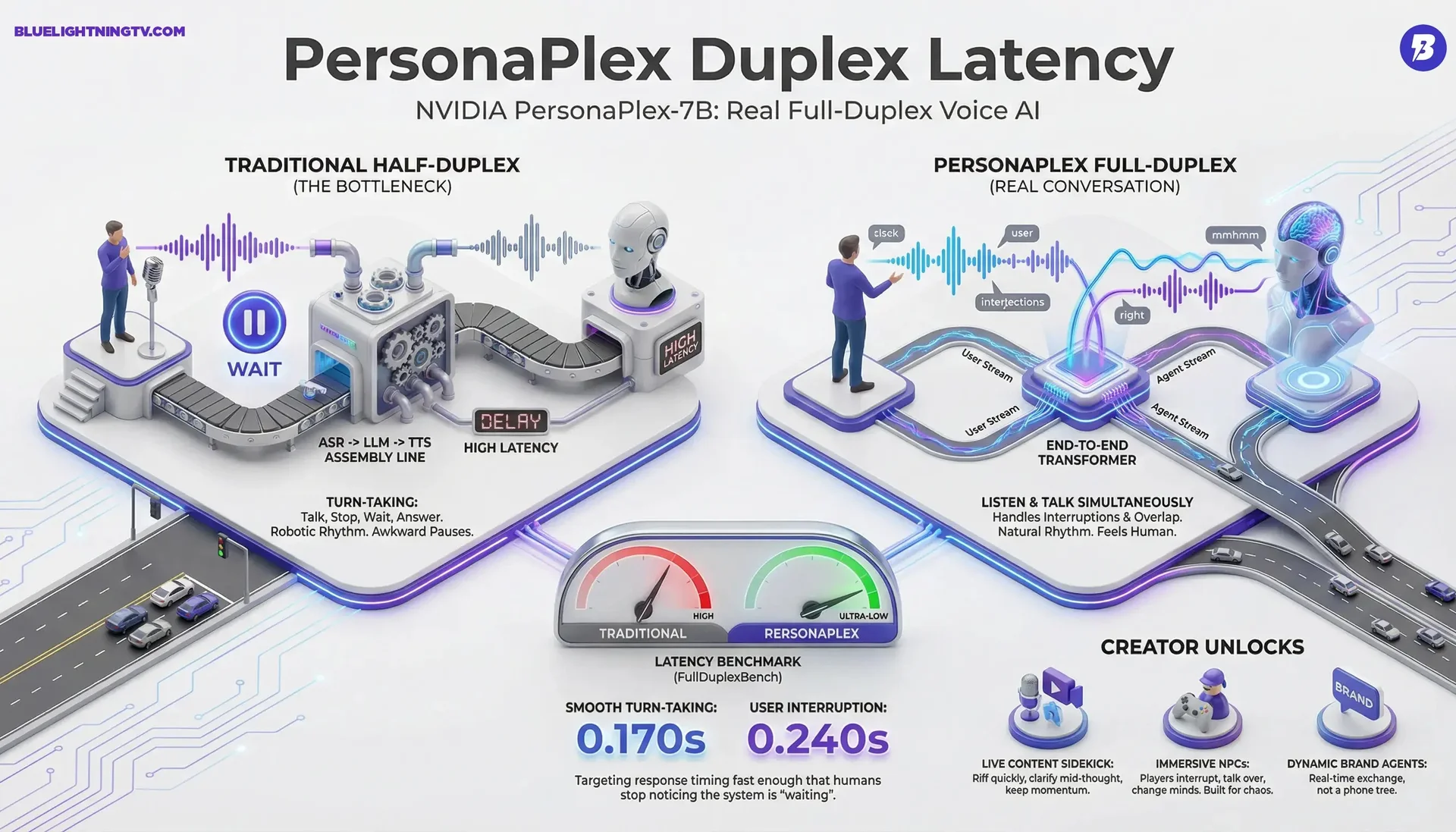
To understand why PersonaPlex matters, you need to understand the compromise that conversational AI has been stuck with for years. Traditional voice assistants — the ones built on what engineers call the ASR → LLM → TTS cascade — are modular. Speech recognition converts your voice to text. A language model thinks up a reply. A text-to-speech engine reads it back. Each piece can be swapped, tuned, and customized. You want a British accent? Change the TTS. You want a friendlier persona? Adjust the LLM prompt. The flexibility is great. The conversation is terrible.
Then came full-duplex models — systems that could listen and speak at the same time, like Kyutai's Moshi. Suddenly the rhythm felt right. Interruptions worked. Backchannels appeared. But there was a catch: you were stuck with one voice and one personality. No customization. No role control. If you were building a customer service bot for a bank, or a patient tutor for a child, or a gruff bartender for a video game — tough luck. You got what the model shipped with.
PersonaPlex is the first system I've used that refuses to accept this trade-off. It gives you the naturalness of a full-duplex model and the customization of a cascade pipeline, wrapped into a single 7B model built on the Moshi architecture that handles everything end-to-end.
Giving the AI a Face (Or at Least a Voice)
The way PersonaPlex handles persona creation is elegantly simple. Before a conversation starts, you give the model two things: a voice prompt — a short audio clip that captures the vocal style you want — and a text prompt — a plain-English description of who the AI should be. A friendly bank teller named Sanni who works at First Neuron Bank. A wise teacher who answers questions with patience. An astronaut named Alex who's dealing with a reactor meltdown on a Mars mission.
That last one isn't hypothetical. NVIDIA actually ships it as a demo prompt, and it's remarkable. The model has never seen anything about reactor physics or space emergencies in its training data, but it stays in character, modulates its tone to convey urgency, uses domain-appropriate vocabulary, and still handles interruptions gracefully. The generalization comes from the Helium backbone, the broadly pretrained language model that sits at PersonaPlex's core, giving it the world knowledge to improvise in situations its conversational training never covered.
The model ships with 16 ready-made voice profiles — eight "Natural" voices tuned for conversational warmth, and eight "Variety" voices with more distinctive character. You mix and match any voice with any role, and none of it requires retraining. It's all prompt-level configuration, which means a developer can spin up a new persona in minutes.
Under the Hood: One Model to Replace the Pipeline
Architecturally, PersonaPlex is built on the Moshi architecture from Kyutai. The Mimi codec encodes incoming speech at 24 kHz into discrete tokens, which then flow through a dual-stream Transformer. One stream — the temporal Transformer — learns conversational rhythm: when to interrupt, when to pause, when to slip in an "oh, okay" that signals understanding. The other — the depth Transformer — handles meaning, intent, and the longer-range reasoning needed to stay in character.
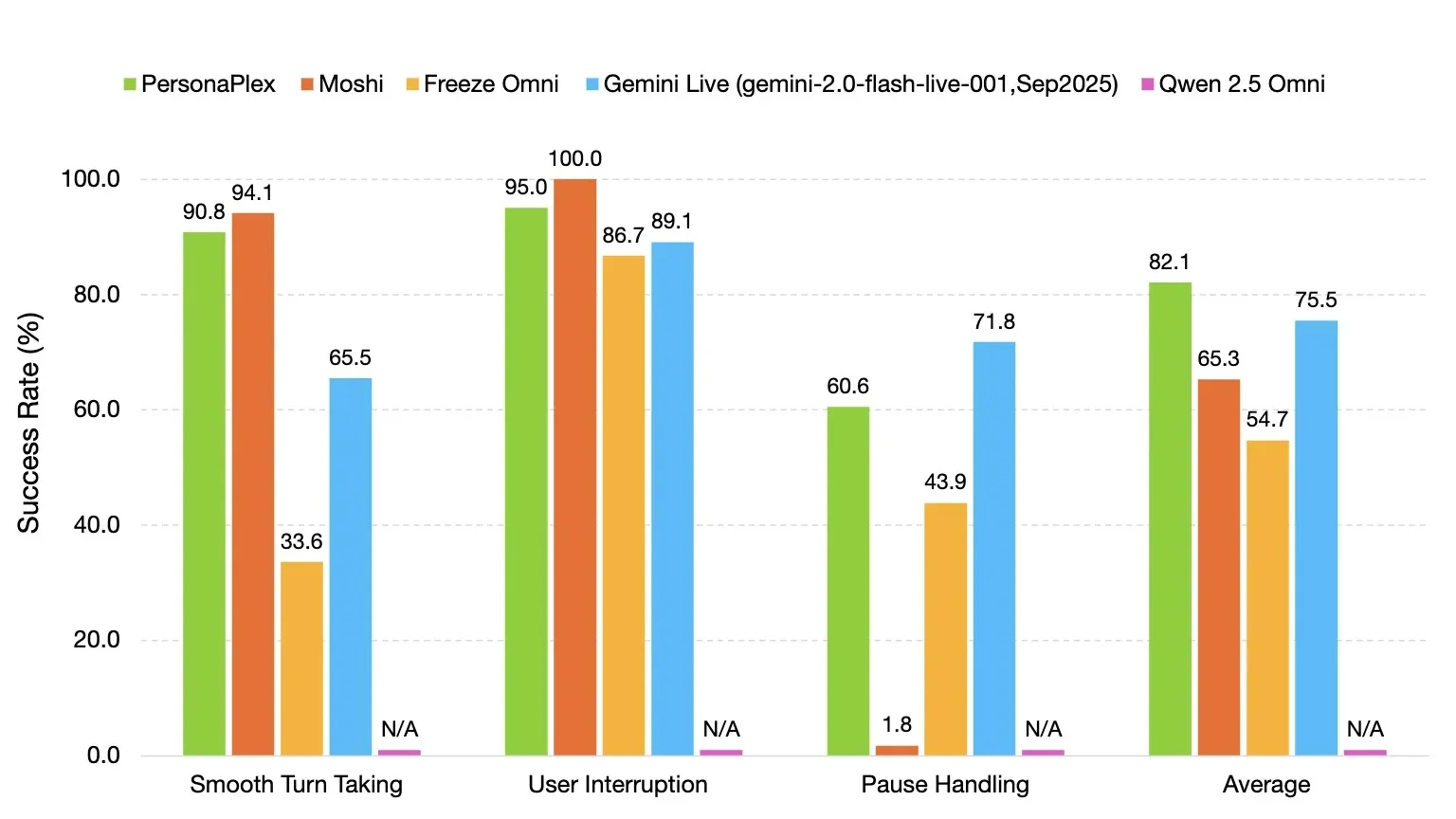
On the output side, a Mimi decoder converts the model's predicted tokens back into speech. Because the entire loop happens within a single model — no separate ASR, no separate TTS — there's no pipeline latency to accumulate. The result is a turn-taking speed of 0.170 seconds and an interruption response time of 0.240 seconds. Those aren't cherry-picked numbers; they come from FullDuplexBench, a dedicated benchmark for this class of model, and the latency benchmarks outperform every open-source and commercial system tested.
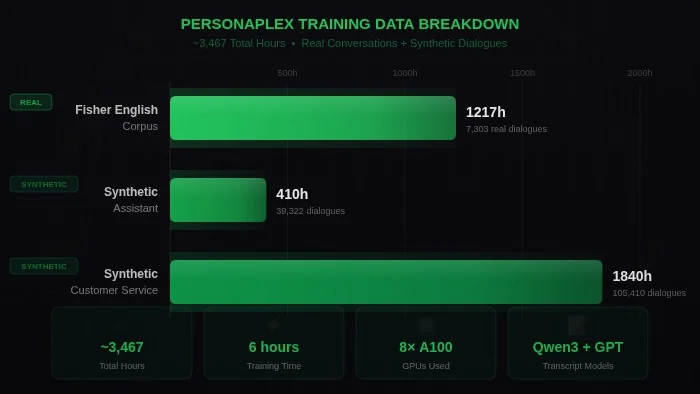
The training data tells its own story. NVIDIA mixed roughly 1,217 hours of real human conversations from the Fisher English Corpus with over 2,250 hours of synthetic dialogues generated by large language models and Resemble AI's Chatterbox TTS. The real data taught the model how humans actually sound when they interrupt, hesitate, and overlap. The synthetic data gave it the breadth of roles and scenarios needed to generalize. The whole fine-tuning process ran for just six hours on eight A100 GPUs.
What It Can't Do (Yet)
I don't want to paint an unrealistic picture. PersonaPlex is English-only right now, which rules out a huge number of real-world deployments. The 7B parameter count means its factual knowledge is limited compared to much larger models — it can hold a convincing conversation, but ask it a complex trivia question and you might get a confident wrong answer delivered in a very human-sounding voice. The text prompt is capped at around 200 tokens, which constrains how detailed your persona description can be.
And then there's the ecosystem problem. Every production voice stack today is built around the cascade architecture. Companies have monitoring dashboards for ASR accuracy, A/B testing frameworks for TTS voices, and prompt engineering workflows for the LLM in the middle. Switching to a unified end-to-end model means rebuilding all of that tooling from scratch — observability, debugging, quality assurance, everything. That's not a small ask.
The Bigger Picture
PersonaPlex is open-source under MIT, with model weights available for commercial use under NVIDIA's Open Model License. The hardware requirements are reasonable: you can run it locally on an RTX 2000 or above with 32 GB of RAM, and NVIDIA recommends 40 GB+ of VRAM for the smoothest experience, though a CPU offload mode exists for smaller GPUs. Getting it running takes just a few commands:
bash
pip install moshi
export HF_TOKEN=<your_token>
SSL_DIR=$(mktemp -d)
python -m moshi.server --ssl "$SSL_DIR"
Once the server starts, the web UI comes up at localhost:8998 — pick a voice profile, type in a persona prompt, and you're talking. An offline batch mode is also available for evaluation, accepting WAV files and producing audio output with JSON transcripts. It is, in every practical sense, something you can go try right now.
I think five years from now, we'll look back at the cascade era the way we look back at dial-up internet — aware that it worked, mildly amazed that we tolerated it for so long. PersonaPlex isn't the model that will get us all the way to seamless human-AI conversation. But it's the model that made me believe we're actually going to get there. And for someone who has been building in this space long enough to be cynical, that's worth a lot more than another benchmark score.
If models like PersonaPlex become widely available, voice assistants could shift from command-based systems to true conversational agents. Real-time interruption, emotional cues, and natural pacing may soon become standard features in AI interaction.
Ready to Transform Your Business with AI?
Let's discuss how our AI solutions can help you achieve your goals. Schedule a free consultation with our experts.
Schedule a Consultation